

They say trust is a delicate thing. It takes a long time to build trust. It's easy to lose and hard to get back.
Trust is built on consistent and ethical actions. Therefore, we must be intentional when creating AI models. It's crucial to ensure that trustworthiness is embedded into our models. As we navigate the AI life cycle, actions must be taken to enhance trust. In this blog series, creating models is the third step among the five pivotal steps of the AI life cycle. These steps – questioning, managing data, developing the models, deploying insights and decisioning – represent the stages where thoughtful consideration paves the way for an AI ecosystem that aligns with ethical and societal expectations.
To ensure we are infusing trustworthiness into our AI models, we should ask a series of questions about how we will build the models and how the models will be used. Questions such as:
1. Are we using sensitive variables? And if we are, should we?
Building a trustworthy AI model hinges on utilizing the right data. While companies gather vast amounts of data in their daily operations, not all data should be used simply because it’s available. For example, does the data you are considering have any sensitive or private information (e.g., health conditions, personally identifiable information (PII))? Does it include any demographic or socioeconomic information (e.g., race, religion)?
Thoughtful consideration must be given to including such sensitive data. It may be available, but that doesn’t mean it should be part of the model. There may even be regulatory or statutory prohibitions on using this type of information. To steer clear of these potential land mines, analyze the data to determine if it is sensitive or private. Using this type of information as the basis of an AI system could inadvertently perpetuate past bias into the future. Similar model results could be attained by aggregating, anonymizing or otherwise masking the sensitive data.
2. Are unfair representations in your training data impacting model predictions?
Unrepresentative training data has the potential to skew a model’s predictions. Imagine a loan approval model trained on historical data where loans were denied to people in certain neighborhoods. This data reflects societal biases, not creditworthiness. The model might then unfairly deny loans to future applicants from those areas, even if they have good credit.
This is just one example – similar biases can creep in based on factors like race, gender or age in areas like facial recognition software or resume screening algorithms. These biases can have serious real-world consequences, limiting opportunities or unfairly targeting certain groups. We need to take steps to have checkpoints in our model-building journey to identify these gaps in data to further prevent skewed model predictability.
3. How will you compare performance and identify disparities across different groups?
Building a trustworthy AI system requires fairness across different groups. Models unfairly slanted toward one group versus another will not be as widely trusted. During the model-building stage, check for fairness with some of these statistics.
• Demographic parity: Each sensitive group of demographic variables should receive the same positive outcome at an equal rate. This can help balance out historical biases impacting the data.
• Equalized odds: Matching both true and false positive rates for different sensitive groups. You want to be sure they are similar between the groups.
• Equal opportunity: Matching the true positive rates for the different sensitive groups. This measures whether the people who should qualify for an opportunity are equally likely to do so regardless of their group membership.
Without identifying disparities, you may inadvertently perpetuate bias from the past into the future. Sometimes, a bias in one category can perpetuate bias in others: Those who get good housing get access to good schools. And the cycle continues.
We want to minimize risk and harm to the most vulnerable populations. If we start from there, all other groups tend to be protected.
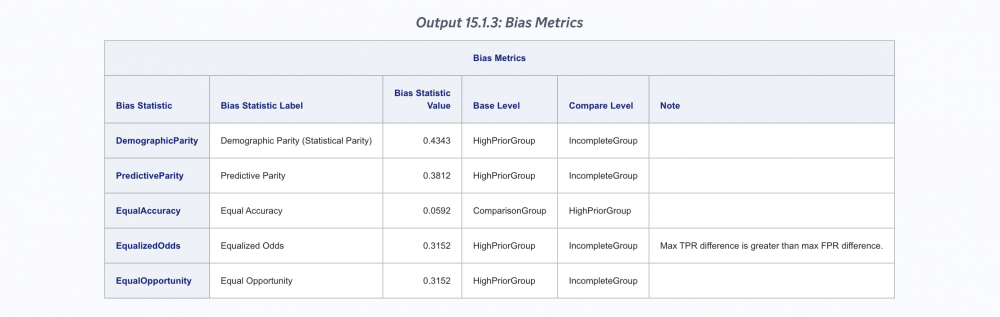
Bias Metrics from Fair AI Tools Action Sets in SAS Studio
4. Have you applied mitigation techniques to any identified biases?
Bias can appear at any stage of the AI life cycle. It can be a part of the training data or the trained model. It is important to mitigate bias because it can lead to unfair predictions for certain groups, often perpetuating biases from the past into the future.
There are three types of bias mitigation techniques that should be considered and are categorized based on where they are deployed in the process:
• Pre-process: Applied to the training data. Identify and mitigate biases in the data before training the model. The intention is that less biased data will lead to a less biased model. Techniques such as anomaly detection, imputation, filtering and transformations are just some examples.
• In-process: Applied to a model during its training. The intention is that a less biased model will lead to less biased predictive outputs. Consider fairness constraints and adjust model parameters during the model training process.
• Post-process: Applied to predictive outputs. Adjust model outputs to compensate for bias in the model.
Left unchecked, bias can creep into your models, impact equity, and lead to disparate educational opportunities, career, housing, health care, access to credit and more.
5. What steps have you taken to explain your models?
There is generally a trade-off between the accuracy and interpretability of AI systems. On the simple end, there are rules-based models. For example, 10(x) + 100(y) + 200 = model output. These models allow you to follow all the data input to the model output. These are easy for the model to “show its work” and are considered transparent models. As you slide down the continuum to other model types (e.g., decision tree, logistic regression), model transparency continues, but they tend to be harder to explain.
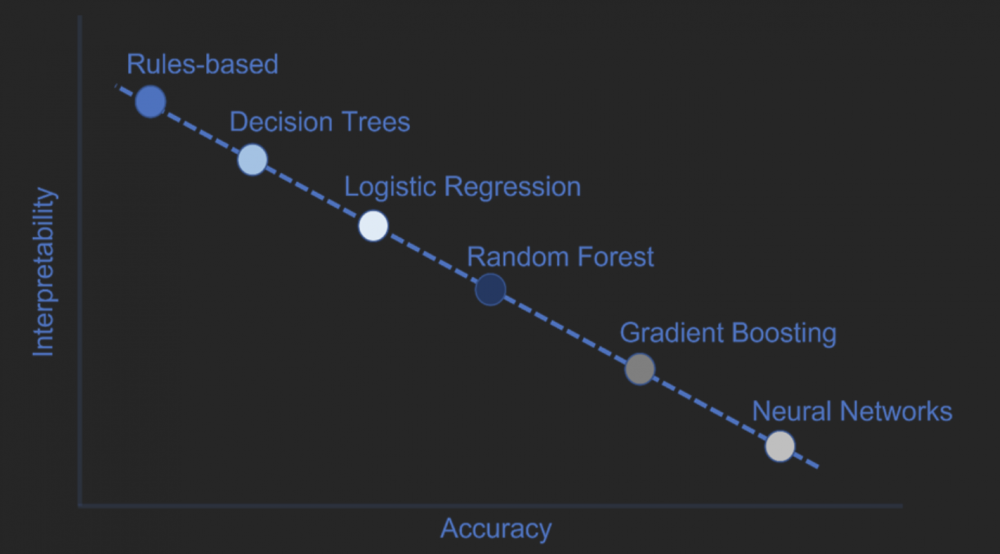
As your model types become more sophisticated, the ability to interpret models quickly and accurately can diminish. Eventually, you may reach a point where you can’t follow all data inputs through to the model output. Instead of a transparent model, you end up with an opaque model. A neural network is a classic example of an opaque model, where there are hidden layers in addition to model input and output.
However, an opaque model does not absolve you of a responsibility to explain the results. This is where the interpretability of AI systems comes into play. There are techniques that allow you to peer into the opaque model to discover meaning and relationships between the data input and the model output – determining how a model came to its conclusions.
Techniques such as PD Plots, ICE, LIME, and HyperSHAP help you interpret your model and detect these relationships.
So why is model interpretability essential? We need to be able to explain models in human terms. For example:
• You may be legally required to confirm that the reason for denying a loan application does not violate any laws that protect certain groups of people.
• Executives need to justify decisions they make based on opaque AI models.
• It helps data scientists to detect bias in training data and model development.
Model development is more than just developing models
Trustworthy AI models don’t just happen. Organizations can ensure their data-driven decision systems are trustworthy by taking deliberate action to identify and mitigate potential biases and to explain how and why decisions were made.
Steve Mellgren is Senior Solutions Architect with SAS’ Data Ethics Practice.

29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
Alleen als In-house beschikbaarWorkshop met BPM-specialist Christian Gijsels over business analyse, modelleren en simuleren met de nieuwste release van Sparx Systems' Enterprise Architect, versie 16.Intensieve cursus waarin de belangrijkste basisfunc...

Deel dit bericht