

Containers are relatively new in IT and are here to stay. In this article I would like to give an introduction of containerization. I hope to explain some use cases and workings by explaining the current most popular platforms in high-level.
Why containerization?
It is not uncommon for companies to have big servers running many different applications. Typically they run many business critical services next to their databases. Every application requires certain frameworks and tooling to be installed. This makes it very hard to maintain. Servers like these require lots of resources and pose risks to the company. Some examples are:
• Installation: applications might require certain or maybe multiple installations of a runtime engine (such as the Java Runtime Engine for Java applications).
• Runtime: the applications are not isolated from each other, which could result in the failure of all applications when one application manages to mess something up.
• Scalability: vertical scaling is not a problem, but has its limits. Horizontal scaling on the contrary is very hard, because multiple of those big servers have to be maintained, and kept in sync with each other.
• Uptime: whenever the server has to undergo maintenance (e.g. for OS upgrades) all applications will be down at the same time.
Most of this can be solved by applying containerization properly. Containers are isolated units which packages the software and all its dependencies together. This ensures a quick startup and a reliable runtime on different environments.
Docker
Docker is the default containerization tool out there. Docker images are the blueprints of a Docker container. Images are described in textfiles, called Dockerfiles. The image contains the necessary OS, applications, libraries, and commands to do a certain job. This enables an endless amount of possibilities. Some examples include running a Python web application, running a database, building Java applications, scanning source-code for security vulnerabilities, and so on.
Docker images can be pushed to Docker registries. Others can download the image, removing the need to build it again. This ensures the same runtime on all stages of a DTAP street. This means that exactly the same application and environment, which has been developed, tested and accepted, will end up on production. Even if the underlying operating systems where Docker runs on are different. “Works on my machine” no more!
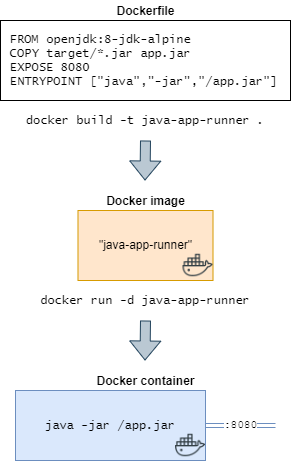
Simplified lifecycle of a Docker workflow.
Running one Docker container is easy, but this is often not enough for a company – especially with today’s microservices hype. Managing a cluster of containers is getting more complicated. Reliably solving complex problems by hand – like networking, scalability, security, and deployments – is very hard to do. There are several tools out there, which can be of great help in these matters. Docker Compose and Docker Swarm are bundled with Docker, but Google’s Kubernetes takes the crown regarding popularity and feature richness.
Kubernetes
Kubernetes can be installed on one server or multiple servers in a cluster. As a client you tell the server what you want the cluster to look like, also known as the desired state. Kubernetes will try its best to make it that way, and keep it that way. An example in the context of a web shop could be the following:
• two containers of the “users” service,
• one container of the “inventory” service,
• a connection between the two containers,
• and an external-facing “users” endpoint.
The above example can be expressed and uploaded to the server using YAML files. In these files everything can be expressed to handle the problems mentioned above. Kubernetes creates abstract layers on top of Docker containers to ensure all of these problems can be solved. These abstract layers are known as resource types. The example above is solved by requesting Kubernetes the following desired state:
• A “Deployment” describing the “users” Docker image, including two replicas.
• A “Deployment” describing the “inventory” Docker image.
• A “Service” which routes an external port to the internal port of the “users” endpoint.
Next to these resources, Kubernetes will create additional resources to make all of this happen. In case of “users” the “Deployment” creates a “ReplicaSet”, which creates two “Pods” containing the Docker containers. The complex problems mentioned above are solved out of the box by using Kubernetes.
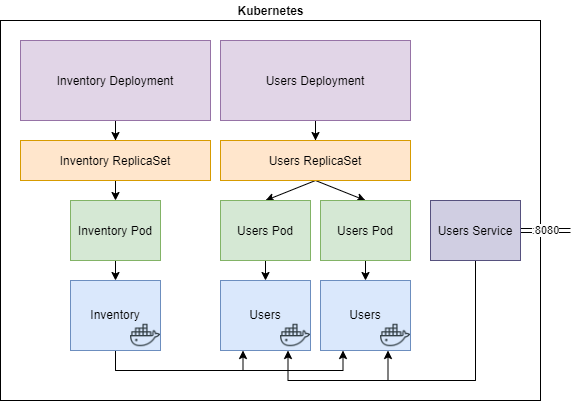
Kubernetes orchestrating multiple Docker containers.
Networking and service discovery
By default pods are deployed to Kubernetes’ internal network. Pods can reach each other by utilizing Kubernetes’ DNS service. A DNS entry is automatically added and assigned to the name of the Pod when it is deployed. This means that the “users” Pod can reach “inventory” just by calling “https://inventory/”, given the HTTPS port is open. There are multiple strategies for load balancing the traffic when multiple replicas of the target pod is deployed. It depends on the setup of the cluster what might be the ideal way to balance the traffic. A round-robin strategy is a straightforward strategy, but might result in a lot of latency when the cluster is distributed among several data centers worldwide.
Scalability
A Pod in a Kubernetes cluster can be deployed with multiple instances at the same time. This can be done by setting the replicas setting in a Deployment to a value of more than one. By using Horizontal Pod Autoscalers Kubernetes can automatically scale the amount of replicas based on certain metrics (CPU by default).
Deployments
Kubernetes offers different strategies of deploying new Pods to the cluster, for example rolling updates. To ensure that a service does not go down during a deployment, this strategy will first deploy the new version of a Pod next to the current version. Once and only when it is fully up, the old Pod will be brought down. This will be done replica by replica. Other deployment strategies allow for example A/B testing, canary testing and many more.
Custom Resource Definitions
Kubernetes offers many different Resource types by its own which gives plenty of possibilities. Kubernetes can be extended with custom resource types, called Custom Resource Definitions. CRDs enable other types of use cases and tooling to profit from Kubernetes’ framework. Some interesting use cases are listed below:
• Not only runtime applications can be dockerized, but also CI/CD pipelines. Tekton extends Kubernetes enabling you to write scalable and “native” build pipelines.
• The Operator Framework allows you to deploy and create applications to your Kubernetes cluster. Typical use cases for this are databases. Databases contain state and have very specific instructions for aspects like upgrading (or downgrading) to other versions. By utilizing the Operator Framework correctly, all of these things can be automated.
Silver bullet?
Kubernetes is the most popular distributed container platform, backed by a very active community. From a user point of view it is great. It offers everything you need when building scalable, highly available and resilient software. There are some downsides that should be pointed out:
• The richness of features is a double-edged sword. A lot of abstraction is added before reaching the Docker container. For newcomers the learning curve is steep, even if they already have Docker knowledge. Definitely when comparing it to lesser extensive alternatives, like Docker Compose or Docker Swarm. To be fair, those are not full alternatives, as they only offer a part of what Kubernetes offers (but it might just be enough for your use case).
• As a software engineer I do not speak from my own experience when talking about the infra side. One downside I often hear is that it is not easy to fully maintain it by yourself. This should definitely be taken into consideration before moving towards Kubernetes. It is not something for an engineer to pick up next to his main task. Luckily some big companies offer managed Kubernetes solutions, like Amazon’s EKS, Azure’s AKS, Google’s GKE or Red Hat’s (cloud independent) OpenShift. Red Hat is not into three letter acronyms, apparently.
• Most engineers love CLI tooling, some love YAML. Be prepared to use them both. Kubernetes’ CLI tool is called kubectl. It is very powerful, but does not always give the most intuitive output. The desired state of the cluster is by default expressed in YAML. While it is designed to be easy to write and read, it can become hard when dealing with big files. Mistakes with indenting are also easily made. Then again, this varies per user and use case.
Conclusion
Containers ensure isolated and consistent runtimes regardless of the environment. They help in making stateless applications scalable and provide easy maintenance. Docker is the most popular tool for creating images and running containers. Kubernetes extends Docker and takes care of orchestrating containers in complex compositions over multiple datacenters. This makes Kubernetes excellent in running scalable, highly available and resilient software. Its vast amount of features makes Kubernetes powerful, but comes with a price of complexity.
Martin Kanters is IT-consultant bij Info Support.


29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
Alleen als In-house beschikbaarWorkshop met BPM-specialist Christian Gijsels over business analyse, modelleren en simuleren met de nieuwste release van Sparx Systems' Enterprise Architect, versie 16.Intensieve cursus waarin de belangrijkste basisfunc...

Deel dit bericht