

In the age of AI, data - and specifically data quality - is a bottleneck. The same situation occurred with code 50 years ago, but it was fixed. How? And what is there for today's data executives to learn?
Custom software development was a competitive advantage for companies and countries back in the day, yet productivity and quality left a lot to be desired. The problem became known as the “software crisis,” and its symptoms were:
• Late and over-budget delivery
• Unused code that was therefore of no value
• Code that was used in production but with sharply increased maintenance costs
• Overall maintenance costs that far exceeded development costs
• Fragility, where small internal or external changes could lead to big errors
• The risk of defects, whose cost increased rapidly with the age of the defect
• Real-time access that was much more expensive than batch access
• ROI that fell short of expectations
• High rate of project failure
Sound familiar?
Key innovations that improved code development productivity and quality, and which are directly applicable to data, were the rapid iteration of agile development and close collaboration of owners and users. This blog post will unpack both of these and how they can be applied today to improve processes for AI, allowing for more efficient implementation and bringing organizations closer to the goal of Everyday AI.
Over the years, code development has moved from the waterfall model to an agile process:
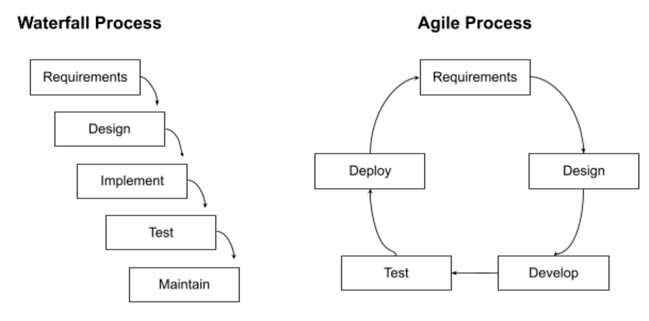
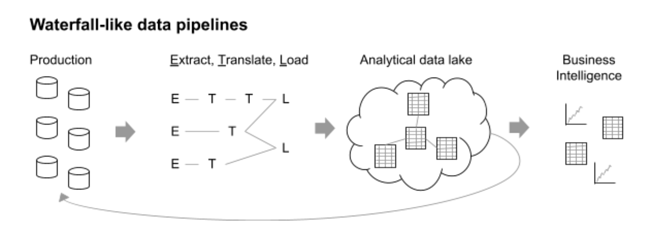
The time between product releases dropped from months to hours — owners communicated frequently with users, and vice versa, allowing them to say less per interaction and lower the risk of the relationship. Many data pipelines today are developed more like the waterfall model than an agile process, with data moving from one phase to the next and with iteration often taking months:
The tipping point for code productivity and quality was arguably the development of Linux, which was a huge success. Linux is used by 100% of supercomputers, 96% of the top million web servers, 90% of cloud infrastructure, and — including its descendent Android — 70% of smartphones.
Its breakthrough wasn’t technical; the tech was derivative. And it wasn’t the people, although the project did upskill thousands of programmers. The breakthrough was a simple process that enabled 10,000 people from over 1,000 companies to co-develop high-quality, mission-critical software.
Vital features of the process were rapid iteration and treating users as co-developers — users contributed code, and if they found a bug, they could fix it rather than just describe it. If a user thought of a useful new feature, they could implement it rather than just document it. Treating users as co-developers allowed teams to expect more from code owners without increasing costs or decreasing velocity because work was distributed — shared — with hundreds of users who had a self-interest in improving the owner’s code.
When it comes to today’s data landscape and AI initiatives at a macro level, increasing the number of people involved, as with software development, solves three key problems:
1. Prioritization: Is the data, use case, insight, etc., important for the business? Most people working on the tech side don’t have this critical insight without external input.
2. Productivity: With better prioritization of business-impacting projects comes more open dialogue between teams, spurring productivity gains.
3. Quality: Does the data (or the result of a model) actually make sense? End users can often find problems quicker than owners can.
Ultimately, as the variety and velocity of data increases — as does the number and kinds of people working with data on a day-to-day basis — data owners can’t possibly know what all their users need.
Consider a customer relationship management (CRM) dataset that I worked on a few years ago. It had one row per U.S. adult and 2,500 variables such as gender, age, education, household income, car model, and the likelihood of owning a dog. The data owner had worked with the dataset for more than 10 years, so everything about it was clear to him.
However, as we began to scale AI across the company, many users were learning about demographic, attitudinal, and behavioral data for the first time. The needs of the dataset’s 100th user were very different from those of its 10th user.
Imagine if the 100th user could prototype a dashboard that fits their needs, make it available to the data owner, and the data owner makes it available to all users. That would help the 200th user more than anything the data owner or the 10th user could do. Quite simply, the 100th user usually understands the 200th user better than the owner does — users learn from users, and the owner coordinates.
This is exactly the role of AI platforms like Dataiku, which — compared to the waterfall-like data pipeline sketched above — is more agile, allows people to leverage many data lakes and marts, and enables rapid iteration between data owners and users (or, more broadly, AI builders and AI consumers). The result could look like co-developed data, wikis, dashboards, statistical workbooks, etc., but the bottom line is increased efficiency.
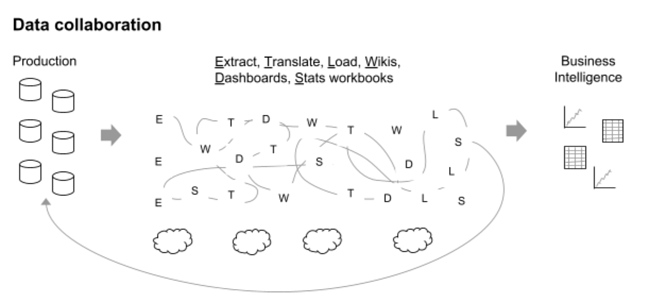
A criticism we sometimes hear when discussing this topic with data engineers, AI developers, and machine learning operations managers is that it’s overly simplistic. True, there are many other things that are valuable in scaling a data-driven culture, such as data governance, computation resource governance, best practices, training, certification, evangelism, reusable templates, gamification of collaboration, continuous process improvement, and a sustainable learning community.
However, as the open source community has shown over and over again, the core of efficient AI practices across an organization are agility (rapid iteration) and not only increasing the number of people involved in AI projects, but opening communication lines between those people, whether owners, builders, users, or consumers of data and AI products.
It's Time to Optimize Your AI Practices
More efficient AI practices come down to more people with more diverse skill sets working with data. Get ahead of the game with “The Do’s and Don’ts of Hiring & Upskilling for AI Talent.”
Doug Bryan is AI Strategist at Dataiku.


29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
Alleen als In-house beschikbaarWorkshop met BPM-specialist Christian Gijsels over business analyse, modelleren en simuleren met de nieuwste release van Sparx Systems' Enterprise Architect, versie 16.Intensieve cursus waarin de belangrijkste basisfunc...

Deel dit bericht